Comme tout ce qui n’est pas testé ne fonctionne pas, tout développeur a forcément des erreurs à corriger dans son code ; je laisse la démonstration de cette assertion au lecteur. D’après mon expérience, la capacité à bien utiliser les outils à sa disposition pour analyser les erreurs dans son programme est un des facteurs ayant le plus d’impact sur la rapidité des développeurs à livrer une application opérationnelle, d’autant plus pour les applications webs qui sont constituées de nombreuses couches de code interagissant les unes avec les autres. Sans prétendre à l’exhaustivité, cet article va vous donner les quelques pistes à explorer pour accélérer le processus d’analyse.
RTFL! (Read the Fucking Logs!)
De très nombreuses bibliothèques, frameworks et autres environnements d’exécution comme les navigateurs internet ou les machines virtuelles – et même les systèmes d’exploitation eux-mêmes – ont la politesse de créer des journaux dans lesquels on peut trouver des informations sur l’exécution des programmes. Rien n’est plus exaspérant pour un référent technique comme moi que de voir arriver un développeur coincé, de lui demander « que vois-tu dans les logs ? » et de s’entendre répondre « je ne sais pas, je n’ai pas regardé… ». Voici une liste de journaux utiles.
Notre framework utilise log4net de l’Apache Software Foundation pour journaliser ses opérations ; par exemple, en mode ERROR, toutes les requêtes SQL provoquant une exception sont écrites dans le journal, et en mode DEBUG, toutes les requêtes y sont écrites. Si vous souhaitez ajouter une journalisation à vos programmes, je vous conseille log4net et ses équivalents sur d’autres plateformes, l’ancêtre log4j, log4php, etc. qui sont peu invasifs, performants, flexibles et possèdent de nombreuses méthodes d’écriture (fichier, journal d’évènement sous Windows, email, console, bases de données, trace ASP.NET, socket, etc.).
PHP peut afficher les erreurs dans la sortie HTML, ce qui est une très mauvaise idée pour des raisons de sécurité ; du coup, les administrateurs désactivent généralement complètement la journalisation des erreurs, alors qu’elles peuvent être très facilement envoyées vers un fichier précis ou vers les journaux système. Quand je débarque dans un code PHP inconnu, je commence généralement par activer la sortie des erreurs, et là c’est festival avant même d’avoir commencé à corriger les problèmes qu’on m’avait soumis !
Sous Windows, le journal d’événements est une mine d’or d’informations pour le débogage. Les services du système d’exploitation y écrivent toutes leurs erreurs, par exemple IIS ou le service de relais SMTP qui y met les messages d’erreur des serveurs SMTP distants. La machine virtuelle .NET y journalise les exceptions non interceptées avec la pile d’appels au moment de l’erreur. L’onglet « Sécurité » contient les erreurs d’authentification et, encore plus intéressant, les traces des audits d’accès aux ressources. Ce dernier outil, assez méconnu, est un don du ciel quand vous ne comprenez pas un problème d’accès à un fichier ; en effet, plus les problématiques de sécurité se font prégnantes, plus les systèmes d’exploitation ont tendance à faire exécuter les programmes par des profils à faibles autorisations, voire à ne pas charger totalement les profils – une spécialité de Windows. Si vous souhaitez comprendre pourquoi vous n’avez pas accès à tel ou tel fichier, vous devez effectuer les opérations suivantes :
- cibler la ressource
- activer l’audit sur la ressource (pour un fichier ou un répertoire, aller dans ses propriétés, onglet Sécurité, cliquer sur Avancé puis aller dans l’onglet Audit et activer les audits utiles)
- activer l’audit sur la machine ; pour cela, aller dans Stratégie de sécurité locale dans les Outils d’administration, déplier Stratégies locales puis Stratégies d’audit, et activer les échecs et/ou les réussites sur la catégorie qui vous intéresse
- réitérer la tentative d’accès
- lire le journal Sécurité, dans lequel vous saurez quel utilisateur a tenté avec ou sans succès à la ressource, depuis quel programme, etc.
- une fois les problèmes réglés, désactiver les audits pour éviter de graver le journal pour le plaisir
Les systèmes de gestion de bases de données relationnels peuvent, en fonction de leur configuration, écrire des traces des requêtes erronées – configuration par défaut de PostgreSQL – ou des requêtes coûteuses – configuration par défaut de MySQL. Ils supportent tous l’instruction EXPLAIN donnant le plan d’exécution, ont des outils de trace avancés, tiers ou natifs, capables de proposer des index pour accélérer les requêtes.
Les navigateurs internet modernes ont des outils pour les développeurs qui auraient fait baver le petit François à ses débuts de développeur web en 1997 : console avec toutes les erreurs, suivi de variables javascript, débogueur avec points d’arrêt et instruction d’entrée dans le débogueur (debugger), liste de règles CSS appliquées à un élément et possibilité de tester des modifications sur icelles, liste des ressources chargées avec source du chargement, temps d’attente du premier octet, temps de téléchargement, en-têtes HTTP en entrée et en sortie, remis en forme indentée des fichiers javascript compressés, manipulation du code HTML, simulation de résolutions tierces et d’interfaces utilisateur tactiles…
Les débogueurs modernes peuvent prendre la main sur un programme déjà lancé, sur la machine locale ou même sur une machine distante, en s’attachant à ce programme, en dehors de leur capacité bien connue de lancer un programme directement en mode débogage.
Et même quand vous n’avez pas accès à la machine, localement ou à distance, vous pouvez demander à l’utilisateur de faire un export mémoire exploitable par votre débogueur, par exemple avec procdump et Visual Studio pour Windows, natif ou .NET.
En bref, avant quoi que ce soit d’autre, RTFL!
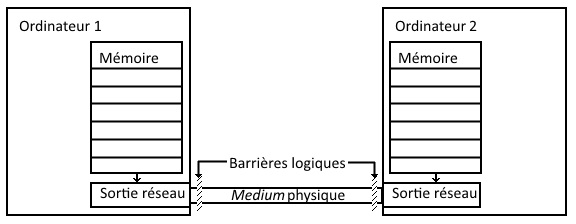
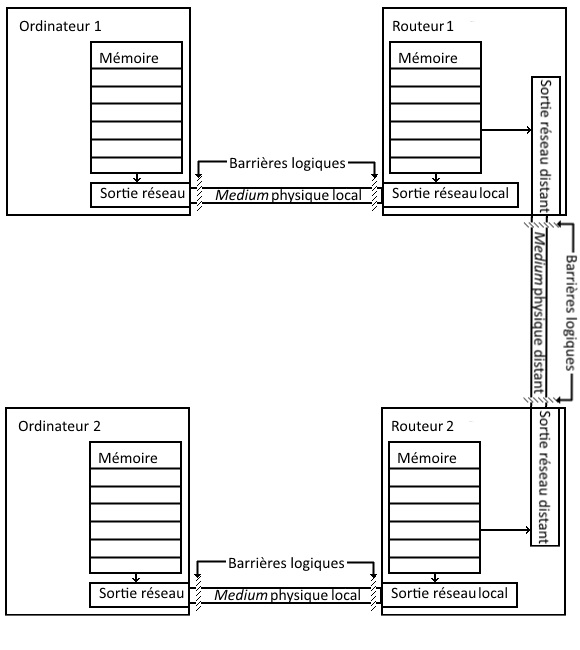
Le mille-feuilles de l’informatique distribuée
Très longtemps, les programmes informatiques se sont exécutés sur une machine unique, sans collaboration avec d’autres ; au pire, on avait affaire à un serveur tout-puissant et un terminal d’affichage stupide.
Aujourd’hui, avec les développement des réseaux, le gros des applications d’entreprise et même grands public distribuent les tâches à plusieurs ordinateurs collaborant pour rendre le service attendu. C’est en particulier le cas du développement web, où vous avez au minimum un serveur manipulant des données de référence pour les rendre intelligibles et modifiables par un client exécutant l’interface utilisateur dans un navigateur web. Le cas général comprend côté serveur des systèmes de stockage de données ayant leur propre langage, SQL ou non, un serveur web pour gérer les connexions réseau, une plateforme logicielle intégrée au serveur web pour tout lier, et côté client du code HTML et CSS définissant l’apparence des écrans et du code javascript pour gérer l’interaction avec l’utilisateur.
En cas de bogue, la couche dans laquelle il survient est rarement difficile à trouver, même si certaines erreurs réseau peuvent être un peu plus vicieuses – comme les validations de certificats SSL. Par contre, il peut s’avérer nettement plus compliqué de déterminer dans quelle couche la correction doit être effectuée : si la reptation jusqu’au client d’une donnée stockée dans une base relationnelle provoque une erreur dans le code javascript, par exemple une « ‘ » non échappée dans une chaîne de caractères, l’erreur se manifeste dans le code javascript exécuté sur le poste du client, alors que la correction à apporter doit l’être dans le code serveur le générant – et pas dans la base, dont les données doivent être agnostiques de la façon dont elles seront utilisées.
Il n’existe pas de règle s’appliquant à toutes les architectures distribuées pour débusquer ce genre d’erreurs, mais en être conscient est déjà un début de solution.
Utiliser les moteurs de recherche
Quand j’ai commencé à programmer, internet n’existait pas pour le grand public ; nous n’avions comme seules ressources que la documentation du langage – 700 pages sur papier bible pour Turbo Pascal 5.5 – et les articles de magazines et livres que nous pouvions trouver en français, autant dire pas grand chose.
Aujourd’hui, il est rare de tomber sur un problème dont personne n’a publié la solution sur internet, mais encore faut-il savoir comment chercher.
Première règle : chercher en anglais. On peut hurler à l’hégémonie anglo-saxonne autant que l’on voudra – j’écris en français volontairement pour créer du contenu francophone sur l’informatique – malgré ses 275 millions de locuteurs, notre langue est loin d’être la plus présente sur internet. Si votre message d’erreur est en français – ou dans n’importe quelle autre langue – traduisez-le du mieux que vous pouvez ; les systèmes de suggestion automatiques peuvent vous aider, et certains services existent pour certaines plateformes. Petit à petit, à force de parcourir les documentations et forums en anglais, vous acquerrez le vocabulaire ad hoc. En désespoir de cause, pour des plateformes traduisant les messages d’erreur en utilisant les paramètres régionaux comme .NET ou Java, vous pouvez forcer la langue d’exécution du programme pour obtenir le message d’erreur en anglais.
Deuxième règle : même si vous cherchez sur un site précis, n’utilisez pas la recherche intégrée du site, utilisez votre moteur de recherche préféré et sa fonctionnalité de limitation à un nom de domaine. Google ou Bing indexent mieux les sites que les sites eux-mêmes, et ils supportent la notation site:nomdedomaine.tld. De toutes façons, les meilleures ressources en dehors des documentations officielles, comme stackoverflow.com ou codeproject.com, sont par nécessité très bien construits pour les moteurs de recherche.
Troisième règle : si le message d’erreur ne donne pas de résultat, passer aux noms des fonctions employées assortis de mots clés correspondant à l’erreur et du langage de programmation ou la plateforme – .NET et Java par exemple ont tendance à avoir des noms d’objets assez semblables – et ça vous évite aussi les pages visant le grand public plutôt que les développeurs – les utilisateurs aussi voient des messages d’erreur. Les noms de méthode dans la pile d’appel peuvent aider à cibler plus précisément la recherche.
Enfin, si jamais vous résolvez un problème sans en passer par internet, ou après une longue recherche et un croisement de plusieurs ressources, rendez la solution disponible pour les copains !