De nombreuses réflexions que je me fais depuis plusieurs années sur internet, les contenus qui y sont publiés et les dispositifs permettant d’y accéder se sont cristallisées d’un seul coup dans mon esprit en une idée de série d’articles à la lecture de cette tribune d’Hossein Derakhshan, blogueur irano-canadien qui à sa sortie de prison en Iran a découvert un paysage de la diffusion de contenus sur internet nouvellement dominé par les réseaux sociaux. Je ne partage pas totalement le pessimisme de ce texte, mais il pose des questions extrêmement intéressantes sur l’évolution actuelle d’internet, auxquelles je vais tenter d’apporter des réponses solidement ancrées dans la technique mais à la portée universelle.
Pour ce premier article, je vais me pencher sur les racines techniques d’internet qui ont défini son identité et assuré son succès.
Internet, le réseau des réseaux
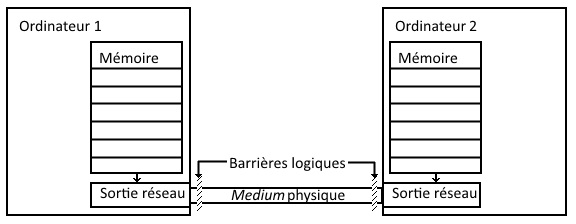
Les premiers réseaux informatiques liant des ordinateurs entre eux datent de la fin des années 50, et reliaient des machines physiquement proches et en tout état de cause, la communication se passait de façon homogène, c’est-à-dire que d’une manière logique, l’information transmise ne traversait qu’une seule barrière, la limite qui sépare un ordinateur du medium physique la transportant jusqu’à l’autre ordinateur.
Les années 60 virent le développement des réseaux locaux, et ce qui est considéré comme le premier réseau interconnecté, ARPANET, est né en 1969. Il fonctionnait de la façon suivante : des machines locales étaient toutes reliées à un ancêtre de routeur appelé IMP via une liaison série maison, et ces IMP discutaient entre eux en utilisant des liaisons téléphoniques dédiées – il est amusant de noter que la première RFC (Requests For Comments, forme de documents de spécifications des éléments techniques d’internet) décrit le fonctionnement des IMP. Les deux points révolutionnaires de cette approche sont la notion de commutation de paquets, et la capacité à traverser plusieurs barrières logiques avec des media physiques potentiellement différents pour transporter les données offerte par le routeur.
Jusqu’à l’invention de la commutation de paquets, une ligne de communication était dédiée à une conversation unique, comme avec le téléphone ; chaque paquet transporte l’information de la source et de la cible, de façon à ce que tous ceux qui empruntent la ligne de communication sachent si l’information leur est destinée.
Le routeur, quant à lui, est là pour gérer le trafic allant et venant vers les réseaux distants ; c’est un traducteur, connaissant à la fois la langue et les personnalités locales, ainsi que l’espéranto commun et les communautés distantes.
Le schéma précédent devient :
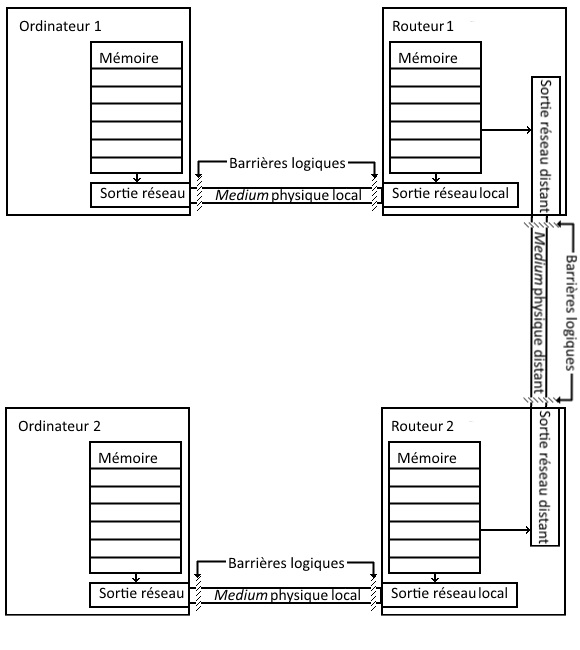
Une fois ce modèle mis en oeuvre, petit à petit, étape par étape, en améliorant les protocoles de communication, en étendant le nombre de routeurs traversables pour lier deux machines, s’est créé au début des années 90 un réseau mondial, auquel la plupart des réseaux locaux sont connectés.
Internet est donc à sa source même une technologie reliant des ordinateurs entre eux, sur la base de langages techniques appelés protocoles, sans donner d’importance particulière aux nœuds, si ce n’est aux routeurs qui ont comme rôle spécifique d’assurer des ponts entre des réseaux hétérogènes.
L’hypertexte, réseau des contenus
Tout cela est bel et bon, mais comme les ordinateurs ne sont que des machines sans intelligence, il faut bien que la communication entre les machines serve à convoyer des informations intéressant les êtres humains. Un service auquel on pense immédiatement est le partage de fichiers distants où un serveur met à disposition une liste de fichiers accessibles ; le protocole FTP remplit ce besoin dès 1971 avec la RFC 114. On peut résumer l’architecture de partage de contenus ainsi créée par le schéma suivant :
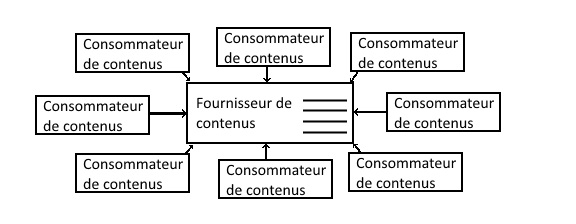
Ce qui frappe immédiatement dans cette organisation, c’est qu’elle ne correspond pas à l’organisation technique des machines ; autant le transfert de données bas niveau entre ordinateurs est par essence décentralisé et symétrique, autant dans ce mode, la consommation de contenus est centralisée et asymétrique. D’un point de vue fonctionnel, elle limite le partage d’informations ; d’un point de vue technique, elle pose de gros problèmes de performance car certains nœuds du réseau, ceux qui servent le contenu, doivent être traités différemment des autres car ils seront plus sollicités. On peut noter cependant qu’elle correspond assez bien à l’idée juridique que les pays développés se font de la propriété intellectuelle.
En réponse à cette inadéquation fonctionnelle de la fourniture de contenus avec les possibilités techniques du réseau, a été créé au CERN par Tim Berners-Lee et Robert Cailliau le World Wide Web, un réseau des contenus, avec comme notion fondamentale le lien hypertexte qui permet à un document de faire référence à un autre document, parfois sur le même serveur de contenus, parfois sur un serveur à l’autre bout du monde. Comme vous avez pu le constater avec mes magnifiques schémas ci-dessus, faire un graphique parlant de ce réseau de contenus est au-delà de mes capacités ; je me contenterai donc de reprendre un exemple de représentation visible dans wikipedia :

La question technique posée par la centralisation des serveurs de contenus n’est pas résolue par cette solution ; c’est le rôle des CDN (Content Delivery Network) qui dupliquent les contenus sur des machines au plus proche des consommateurs, et du peer to peer, qui distribuent la responsabilité de fournir le contenu à un maximum de nœuds dans le réseau, mais c’est une autre histoire.
Conclusion
S’appuyant sur ces deux technologies, Internet est prêt à envahir le monde : un réseau extensible d’ordinateurs et un réseau extensible de contenus, marchant la main dans la main, construits principalement par la communauté scientifique, dans un soucis de partage du savoir et de la puissance de calcul. Dans le second article, nous verrons ce que la première phase de l’ouverture au grand public en aura fait.

Une réflexion sur « Etat de l’internet en l’an 10 des réseaux sociaux (1) : les prémisses »